ミネストローネ
トマト感抜群のミネストローネのレシピです。

材料(4食分=2人で食べて、それぞれおかわりできる)
- キャベツまたは白菜(2~3枚)
- じゃがいも(2~5個)
- 人参(1本)
- ハム(1パック)
- 玉ねぎ(1個)
- コンソメの元 固形タイプ(2個)
- オリーブオイル少々
- 胡椒
- 塩少々(使わなくてもOK)
- 水 300ml
下ごしらえ
- じゃがいも、人参、ハムは1cm角に切る
- キャベツまたは白菜は1cm角より若干大きめにざく切り
- 玉ねぎはみじん切り
調理
- 鍋にオリーブオイルをしく。
- 玉ねぎを炒める。
- 玉ねぎの色が変わる前に、じゃがいも、人参を鍋に入れて一緒に炒める。
- 中身がしんなりしてきたら、ハムとキャベツまたは白菜を加えて軽く炒める。*1
- トマト缶, 水300 mlを加えて10分ほど煮立てる。*2
- 煮立ててる途中にコンソメ、胡椒、塩で味を整える。 塩は少なめ、胡椒は多めがおすすめです。
水分少なめでトマト感をガツンと感じれる一品です。スープというよりおかず感覚で楽しんでください。
AWS ソリューションアーキテクト アソシエイト を一ヶ月で合格
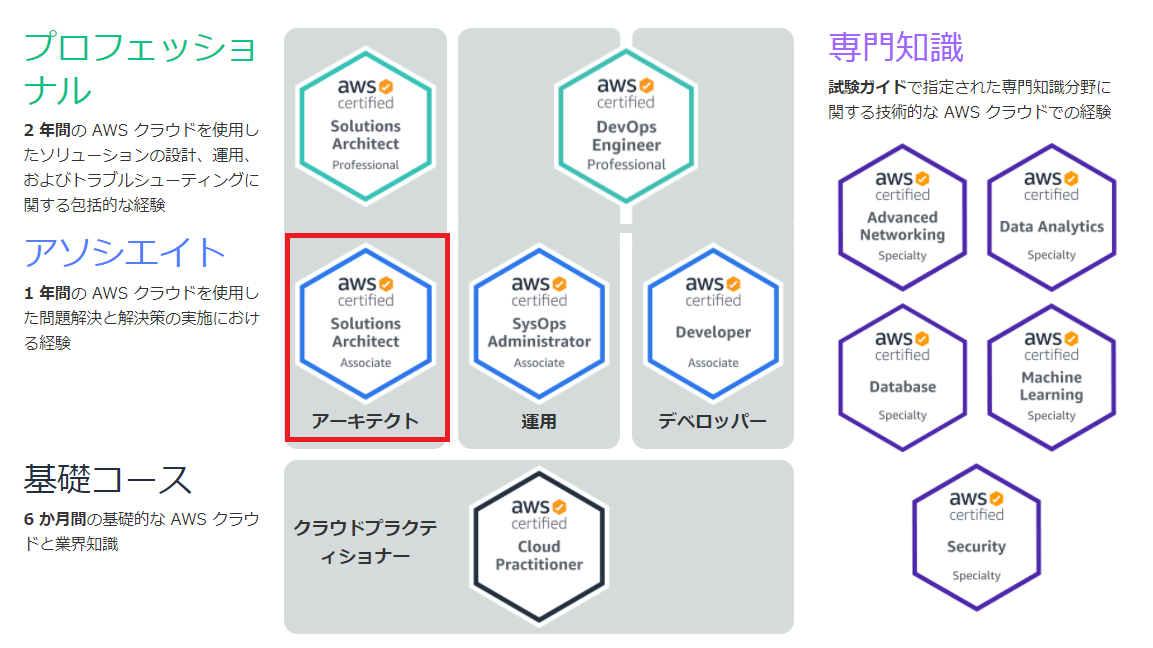
AWS認定試験 ソリューションアーキテクトとは
- リンク中の試験区分において中段のアーキテクトの位置する。
- 難易度は最も基礎的なクラウドプラクティショナーと、プロフェッショナルの中間的な立ち位置。
- 他のブログ記事を見ても、さほど高い難易度ではないものの、AWS特有のサービスに対する理解が必要。
想定読者
- 本記事の想定読者は、AWS ソリューションアーキテクト アソシエイトを受験することを決めた/迷っている人
筆者の初期レベル
- 情報工学学科の大学・大学院を修了
- データ分析業務を行う入社5年目以内の若手社員
- 専門分野は統計学・機械学習など
- ネットワーク・セキュリティの知識は学部時代の講義レベル
- AWSの実務経験なし
- その他、IPA応用情報技術者保有
勉強方法
- 勉強期間:2021年7月頭から7月最終週の約一ヶ月間
- 平日は仕事帰ってから(7月は残業が多く勉強できない日が半分くらいありました)
- 休日は1日3~5時間程度
- 初めの一週間は
この本を読みました。
- この本の内容で最低限必要な知識がだいたい身につきます。
- ただし、例題や最終章の問題は本番の試験と比べるとかなり簡単なので要注意。
- この本だけでは足りない細かな知識もたくさんあるので、他の問題集やブラックベルトなどを読む必要がある。
- それ以降は問題集を購入して、解く→解説を読む→解説がわからない箇所は上記本やインターネット検索で補強を繰り返す。
- 購入した問題集はUdemyと, whizlabs
- Udemyの方は難易度が高く、4つくらいしかやれませんでした。
- whizlabsはスマホにGoogle Chrome を入れて、翻訳機能を使いながら問題と解説を読みました。
- 自動翻訳なので所々おかしいところがありますが、本番の試験も同様に、変な日本語が混ざるので、それも含めて良い練習になります。
- 個人的にはwhizlabsだけを購入してやり込めばOK。
試験当日/当日までにすること
- 自宅からWEBで試験を受けることができます。
- 試験中はカメラとマイクをオンにした状態で試験を受けます。
- 試験前に机や周辺を状況を試験管にWEBカメラを使って見せなければなりません。(ノートPCに付属のカメラでOK)
- 試験前日までに本棚にカーテンのようなものをかけるなど、座っているところから文字が一切見えないようにする必要があります。
- 腕時計をつけられません。
- 机の上には、試験で使用するPC以外何も置けません。外部モニターを持っている人は移動させないといけないので一苦労。
- 試験中に考え込んで独り言を言うのも注意されるそうです。
- 身分証明証の準備。外国人の試験官でも、日本の免許証で大丈夫でした。
その他
- 日本人の試験官は予約がすぐに埋めるので、日本人の試験官が良い人は早めに予約しましょう。
- 外国人の試験官の英語はゆっくりなので聞き取れますが、スピーカーの質によっては聞き取れないと思います。
- 外国人の試験官の英語に不安があるけど、どうしても日本人の試験官の日程が合わない場合は、事前に試験サイトの注意事項をよく読み、何が説明されるかをしっかり理解してから試験に挑みましょう。
さいごに
会社の同僚2人と私の3人で、AWSの知識ゼロから1ヶ月で試験合格を目指して勉強をしました。
決して安くない試験料を払って、自宅からWEBでいつでも受けられる試験は、「勉強をしっかりして受けるレベルになってから受験申し込みしよう」と考える人が大多数だと思います。自己コントロールがしっかりできる人ならばそれが良い戦略ですが、後回しになりがちかもしれません。
思い切って受験日を先に決めて、計画的に勉強を進めるやり方は無謀にも見えますが、自らを追い込み、全力で勉強に打ち込める環境を作ることができます。
これを支えてくれたのは、お互いに模擬試験の結果を見せあい、勉強を煽り合いながら高め合えた会社の同僚達であり、とても感謝しています。

牛肉のトマト煮
トマト好きにはたまらないレシピです。

材料 (3人前くらい)
- 牛肉 (400g)
- トマトパック半分
- パプリカ 1個
- 玉ねぎ 1個
- 平茸 適当(他のきのこ類でも良いし、なくても良い)
- オリーブオイル
- 塩コショウ
- コンソメの素
- にんにく(なくても良い)
- バジル(なくても良い)
下ごしらえ
- 野菜を一口大に切る
- にんにくを刻む
調理
- オリーブオイルを引く
- パプリカ→きのこ→玉ねぎ の順に入れて炒める・・・A
- Aをお皿に避ける
- フライパンに牛肉を入れる
- 胡椒を振る
- トマトパック半分・コンソメの素・塩を投入して蓋をせず煮込む
- グツグツしてきたらAを入れて混ぜる
- もう少しだけ煮込む
- 盛り付けたあとにバジルを振りかける
メモ
- コンソメの素は入れすぎず、塩で味を調整する
スペイン風オムレツ (トルティージャ)
下ごしらえ
じゃがいも
- じゃがいもを洗う
- 電子レンジでチンする(根菜モード)
- 皮を剥いて1cm四方に切る
ハム
- 1cm四方に切る
玉ねぎ
- 1cm四方に切る
卵
- 卵を2n個割ってボウルに移す(nは食べる人数)
- 卵をとく(白身を切るイメージ、空気を含ませる)
- 塩、バジル、胡椒を適当に入れる(塩以外は多めでOK)
調理
- フライパンにオリーブオイルを敷く
- 玉ねぎ、ハムを入れて少し炒める
- オリーブオイルをフライパンの周りに追加する
- 卵を一気に流し込む
- フライパンの周りに張り付かないように菜箸で混ぜる
- 固まってきたらフライパンの上に大きなお皿を重ね、お皿にひっくり返す
- ひっくり返した卵をフライパンに戻して裏側を焼く
- 適当なタイミングで火を切り、完成
その他
- じゃがいもが入っていればスペイン風らしい
北海道
登別
帯広
元祖豚丼のぱんちょう
- 帯広名物の豚丼
- 多数有名店があるが、ここも随一の人気店
- 炭火で焼かれた豚の味と香りは格別


釧路
釧路湿原
- 雨の日に行ったので何も見えませんでした。
- 天気は運です。いつかリベンジしたい。
シャケ番茶

- 朝ごはんにいきました。
- ご飯がついてくるのが嬉しい。
- お店の人が焼き加減を見てくれるのでありがたい。
- 魚は個体を自分で選べるのも楽しいところ。
羅臼
知床食堂道の駅


知床峠

- 5月でも雪が見えており、スキーもできるらしい。
- 車で行く際には雪にお気をつけください。
- とにかく景色が良かったです。
網走監獄

- 近くの川を渡ったところに「本物の」刑務所があるので間違わないように注意。
- 中は広く、展示物も多いのでかなり長時間楽しむことができます。
- 筆者は時間都合で1時間強で出ましたが、まだまだ見たかったといった印象です。
旭川
旭川ラーメン「味特」

- 醤油ベースのラーメン
- お好みでバターも
Creamery濃夢 Milk Bar

- 美味しい乳製品がいただけます。
- 小さい店舗ですが、雰囲気の良い店員さんでした。
青い池
- apple製品の壁紙にもなった有名な観光地です。
- 池を見るだけですが、歩く量が多いの所要時間は40~50分をみておいた方が無難です。
札幌
スープカレー
- Soup Curry TREASURE という店でスープカレーを頂きました。辛さがちょうどよく病みつきになります。

札幌ビール工場
無料で工場見学ができます。ビールも無料で2二杯くらい飲めます。



小樽
JR快速エアポート
札幌→小樽の移動は電車で移動しました。JRが通っており、40分前後で移動できます。移動中の景色もとても良いので、進行方向一番前にいるのが良いかもしれません。
食べたもの
- 八角: 身がプリプリで絶品でした。ここでしか食べられないと思っています。
- イカ: イカは噛みきりにくく、あまり好きではないのですがここで食べたイカは絶品でした。イカが好きな人も嫌いな人も食べるべきです。



小樽運河クルーズ
船に乗って遊覧もできます。ガイドさんの説明を聞くと小樽の歴史など、勉強になります。

Twitterの投稿数がポアソン分布に従うか調べる
はじめに
筆者のTwitterの投稿頻度が低いので、筆者のツイート頻度はポアソン分布に従っているのではないか?と考え、χ二乗検定で確認してみました。 その結果、two-part ポアソン分布に従っていることが確認できました。その手続とソースコード1の記録です。
ツイート数の取得
- PCからWEB版Twitterで、自分のアカウントにアクセス
- 「もっと見る」→アナリティクス→ツイートタブ→データをエクスポート→BY DAY を指定してダウンロード ダウンロード時は期間を指定可能(一ヶ月単位でしかダウンロードできない。4~5ヶ月程度取得可能)
分析
フォルダ構成
- DIR_HOME
定数とmain関数
コメントとソースコードの通りで、特に説明することはありません。
import os import glob import numpy as np import pandas as pd import scipy.misc import matplotlib.pyplot as plt DIR_HOME = os.path.dirname(os.path.abspath(__file__)) + os.sep + '..' DIR_DAILY_DATA = DIR_HOME + os.sep + 'daily_data' COL_TWEET_COUNT = 'Tweets published' MAX_TWEETS = 7 def main(): # 月ごとにまとめられた日付ごとのツイートデータファイル名を取得 filenames = glob.glob(DIR_DAILY_DATA + os.sep + '*.csv') # 一日ごとのツイート数を集計 num_tweet_freq = read_daily_data(filenames) # ポアソン分布に従った場合の期待度数を算出 expect_distribution = calc_poisson_distribution(num_tweet_freq) zero_expected_tweet_freq = calc_zero_inflated_poisson_distribution( num_tweet_freq) expected_tweet_freq = expect_distribution * np.sum(num_tweet_freq) # χ二乗検定 poi_text = chi_square_test(num_tweet_freq, expected_tweet_freq) two_part_text = chi_square_test(num_tweet_freq, zero_expected_tweet_freq) text = ' Poisson: ' + poi_text + '\n' +\ 'Two-part Poisson: ' + two_part_text # ヒストグラムの可視化 draw_hist(num_tweet_freq, expected_tweet_freq, zero_expected_tweet_freq, text) if __name__ == '__main__': main()
データ読み込みと集計
def read_daily_data(filenames): num_tweet_distribution = np.zeros(MAX_TWEETS) for filename in filenames: df = pd.read_csv(filename) for tweet_of_day in df[COL_TWEET_COUNT].values: # 1日のツイート数の分布を調べる num_tweet_distribution[tweet_of_day] += 1 return np.array(num_tweet_distribution, dtype=np.float64)
ポアソン分布の分析
今回は2種類の理論分布を調べました。
はじめはシンプルなポアソン分布だけを調べたのですが、ツイート数が0の日がとても多いことからデータへの当てはまりがとても悪く、モデルの検討を余儀なくされました。そこで、ツイート数が0かどうかをベルヌーイ分布に従って決定し、ツイート数が0でなければポアソン分布に従う、というtwo-part Poisson 分布を用いました。
ポアソン分布
ポアソン分布の密度関数は以下のように与えられます。日本語で説明すると、「単位時間あたりに平均 λ 回生じる現象が、単位時間に k 回起きる確率」です。
ポアソン分布には以下のような特性があり自分の感覚としても、この特性は自分のツイート数の分布に合致しているのでは?と思っていました。 - ポアソン分布は低頻度で発生する現象に対して当てはまりがよく、よく使われます。
- 低頻度で発生することでも、一気にたくさん発生することもある。ex) 飛行機事故の分布
- パラメータλは分布の平均値であり、これは分散でもある。
実装ではデータの平均値からパラメータλ(プログラム中の変数mu)を求めています。関数calc_poisson_distributionを参照)
Two-part ポアソン分布
Two-part ポアソン分布とは
普通のポアソン分布で当てはまり具合を調べてみるとツイート数が0の日があまりにも多く(観測値)、理論値と乖離がありました。
実はこのように回数0の頻度がとても多い分布はよくある話で、例えば飛行機事故なんかではそもそも飛行機が飛んでない日があるとするとその日の事故数は0としてカウントされます。
Two-part ポアソン分布のTwo-part とは、
- ベルヌーイ分布によって、そもそも飛行機が飛ぶか飛ばないかを決定
- ベルヌーイ分布の結果に応じて変動
- 飛行機が飛ばないなら事故数は0
- 飛行機が飛ぶならポアソン分布に従って事故数がモデル化される
という、二段階で考えることを意味します。 私の場合でいうと、仕事が遅くまであって疲れてて or 旅行にいっていて Twitterをそもそも開けていない日は当然ツイート数が0になるというわけです。
Two-part ポアソン分布の実装
適切な実装方法はわからないので、適当に実装しています。 データからツイート数0の頻度を計算し、それを0の発生頻度とします。 1以上の頻度に対してポアソン分布のパラメータを計算し、合体させたものを理論度数としています。
その他の対処方法案
- ゼロ過剰ポアソン分布を用いる
ゼロ過剰ポアソン分布は実装が面倒だったので妥協しています。
- 集計期間を広くする
一日のツイート数ではなく、一週間のツイート数など、集計期間を長くとることで分布を調整する方法が考えられます。しかし、この方法ではポアソン分布になるかどうか怪しい & 期間を長くしすぎると中心極限定理が働いて正規分布になってしまって面白くない。
def calc_poisson_distribution(distribution): # (e^{-λ}λ^k)/k! に従うかどうか検定 # λ = 未知母数 (データから推定する) # X = クラス k(K回事象が起こる) # パラメータλを標本平均から推定する mu = calc_mean(range(len(distribution)), distribution) # 推定されたパラメータλからポアソン分布に従う場合の期待分布を求める poisson_distribution = np.zeros(MAX_TWEETS) for x in range(MAX_TWEETS): poisson_distribution[x] = calc_poisson(mu, x) return poisson_distribution def calc_zero_inflated_poisson_distribution(distribution): zero_num = distribution[0] zero_rate = distribution[0]/np.sum(distribution) # パラメータλを標本平均から推定する mu = calc_mean(range(1, len(distribution[1:])), distribution[1:]) # 推定されたパラメータλからポアソン分布に従う場合の期待分布を求める poisson_distribution = np.zeros(MAX_TWEETS) for x in range(1, MAX_TWEETS): poisson_distribution[x] = calc_poisson(mu, x) poisson_distribution[0] = zero_rate after_zero = poisson_distribution[1:] * np.sum(distribution[1:]) return np.array([zero_num] + list(after_zero), dtype=np.float64) def calc_mean(xs, distribution): sum_ = 0 for x, freq in zip(xs, distribution): sum_ += x*freq mu = sum_/np.sum(distribution) return mu def calc_poisson(mu, x): e_mu = np.e ** mu return mu**x / (e_mu * scipy.misc.factorial(x))
χ二乗検定
あるデータが特定の分布に従っているかどうかを判定するにはχ二乗検定を用います2。χ二乗統計量は以下の式で与えられます。
数学的な説明を取っ払うと、観測値と期待値の自乗誤差和を期待値で割って正規化しています。確率変数に基づく計算をやると、χ二乗分布に従うことが確認でき、この値がχ二乗分布から大きく外れているとχ二乗分布であることが棄却され、2つの分布は異なる分布であるという結論が導かれます。
今回の場合は同一の分布であることを確認したいので、χ二乗値が自由度((7-1)×(2-1)=6)の上側有意確率0.05のχ二乗値12.6よりも小さいと嬉しいです。
def chi_square_test(data_freq, expect_freq): def calc_df(shape_): df = 1 for len_ in shape_: df *= (len_ - 1) return df chi_square = np.sum(((data_freq - expect_freq)**2)/expect_freq) df = calc_df(data_freq.shape) text = 'X-squared = {:.4f}, df = {:d}'.format(chi_square, df) print(text) return (text)
可視化
matplotlibで、 - 観測データの分布(Observed) - ポアソン分布の理論分布(Poisson) - Two-parat ポアソン分布の理論分布(two-part Poisson) を可視化しています。
def draw_hist(data_dist, expect_dist, two_part_dist, text): fig, ax = plt.subplots(1) ax.set_title('Target period: 2020/09/01~2020/12/31') ax.bar(np.arange(len(data_dist)), data_dist, width=0.2, label='Observed', color='#008000') ax.bar(np.arange(len(data_dist))+0.2, expect_dist, width=0.2, label='Poisson', color='salmon') ax.bar(np.arange(len(data_dist))+0.4, two_part_dist, width=0.2, label='two-part Poisson', color='lightblue') ax.legend(loc='best') ax.text(1.5, 50, text) ax.set_xlabel('Tweets per day') ax.set_ylabel('freq') plt.show() plt.close()
結果
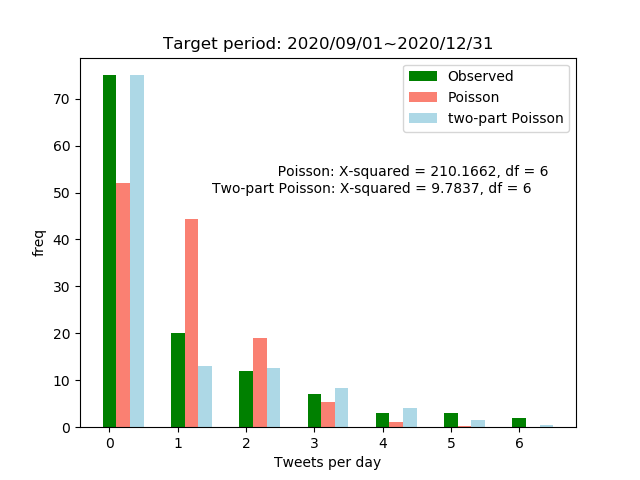
考察(というか感想)
- 無意識にツイートしていただけなのに、(条件はつくものの)ポアソン分布に従うことがわかって驚き
- よくツイートする人なら一様分布や正規分布のような形になるのだろうか。
- ポアソン分布に従っているからといって特に何か知見が得られたわけではない。あまりツイートしていないことが再確認された。
- 普通のポアソン分布の方をRでも一致することを確認済。
o <- c(75, 20, 12, 7, 3, 3, 2)
e <- c(5.20165547e+01, 4.43419811e+01, 1.88998608e+01, 5.37045225e+00,
1.14452261e+00, 1.95131724e-01, 2.77236329e-02)
chisq.test(o, p = e / sum(e))
qchisq(.95, df=6) # χ二乗値の確認 12.59159
# 出力結果:
Chi-squared test for given probabilities
data: o
X-squared = 210.16, df = 6, p-value < 2.2e-16