Twitterの投稿数がポアソン分布に従うか調べる
はじめに
筆者のTwitterの投稿頻度が低いので、筆者のツイート頻度はポアソン分布に従っているのではないか?と考え、χ二乗検定で確認してみました。 その結果、two-part ポアソン分布に従っていることが確認できました。その手続とソースコード1の記録です。
ツイート数の取得
- PCからWEB版Twitterで、自分のアカウントにアクセス
- 「もっと見る」→アナリティクス→ツイートタブ→データをエクスポート→BY DAY を指定してダウンロード ダウンロード時は期間を指定可能(一ヶ月単位でしかダウンロードできない。4~5ヶ月程度取得可能)
分析
フォルダ構成
- DIR_HOME
定数とmain関数
コメントとソースコードの通りで、特に説明することはありません。
import os import glob import numpy as np import pandas as pd import scipy.misc import matplotlib.pyplot as plt DIR_HOME = os.path.dirname(os.path.abspath(__file__)) + os.sep + '..' DIR_DAILY_DATA = DIR_HOME + os.sep + 'daily_data' COL_TWEET_COUNT = 'Tweets published' MAX_TWEETS = 7 def main(): # 月ごとにまとめられた日付ごとのツイートデータファイル名を取得 filenames = glob.glob(DIR_DAILY_DATA + os.sep + '*.csv') # 一日ごとのツイート数を集計 num_tweet_freq = read_daily_data(filenames) # ポアソン分布に従った場合の期待度数を算出 expect_distribution = calc_poisson_distribution(num_tweet_freq) zero_expected_tweet_freq = calc_zero_inflated_poisson_distribution( num_tweet_freq) expected_tweet_freq = expect_distribution * np.sum(num_tweet_freq) # χ二乗検定 poi_text = chi_square_test(num_tweet_freq, expected_tweet_freq) two_part_text = chi_square_test(num_tweet_freq, zero_expected_tweet_freq) text = ' Poisson: ' + poi_text + '\n' +\ 'Two-part Poisson: ' + two_part_text # ヒストグラムの可視化 draw_hist(num_tweet_freq, expected_tweet_freq, zero_expected_tweet_freq, text) if __name__ == '__main__': main()
データ読み込みと集計
def read_daily_data(filenames): num_tweet_distribution = np.zeros(MAX_TWEETS) for filename in filenames: df = pd.read_csv(filename) for tweet_of_day in df[COL_TWEET_COUNT].values: # 1日のツイート数の分布を調べる num_tweet_distribution[tweet_of_day] += 1 return np.array(num_tweet_distribution, dtype=np.float64)
ポアソン分布の分析
今回は2種類の理論分布を調べました。
はじめはシンプルなポアソン分布だけを調べたのですが、ツイート数が0の日がとても多いことからデータへの当てはまりがとても悪く、モデルの検討を余儀なくされました。そこで、ツイート数が0かどうかをベルヌーイ分布に従って決定し、ツイート数が0でなければポアソン分布に従う、というtwo-part Poisson 分布を用いました。
ポアソン分布
ポアソン分布の密度関数は以下のように与えられます。日本語で説明すると、「単位時間あたりに平均 λ 回生じる現象が、単位時間に k 回起きる確率」です。
ポアソン分布には以下のような特性があり自分の感覚としても、この特性は自分のツイート数の分布に合致しているのでは?と思っていました。 - ポアソン分布は低頻度で発生する現象に対して当てはまりがよく、よく使われます。
- 低頻度で発生することでも、一気にたくさん発生することもある。ex) 飛行機事故の分布
- パラメータλは分布の平均値であり、これは分散でもある。
実装ではデータの平均値からパラメータλ(プログラム中の変数mu)を求めています。関数calc_poisson_distributionを参照)
Two-part ポアソン分布
Two-part ポアソン分布とは
普通のポアソン分布で当てはまり具合を調べてみるとツイート数が0の日があまりにも多く(観測値)、理論値と乖離がありました。
実はこのように回数0の頻度がとても多い分布はよくある話で、例えば飛行機事故なんかではそもそも飛行機が飛んでない日があるとするとその日の事故数は0としてカウントされます。
Two-part ポアソン分布のTwo-part とは、
- ベルヌーイ分布によって、そもそも飛行機が飛ぶか飛ばないかを決定
- ベルヌーイ分布の結果に応じて変動
- 飛行機が飛ばないなら事故数は0
- 飛行機が飛ぶならポアソン分布に従って事故数がモデル化される
という、二段階で考えることを意味します。 私の場合でいうと、仕事が遅くまであって疲れてて or 旅行にいっていて Twitterをそもそも開けていない日は当然ツイート数が0になるというわけです。
Two-part ポアソン分布の実装
適切な実装方法はわからないので、適当に実装しています。 データからツイート数0の頻度を計算し、それを0の発生頻度とします。 1以上の頻度に対してポアソン分布のパラメータを計算し、合体させたものを理論度数としています。
その他の対処方法案
- ゼロ過剰ポアソン分布を用いる
ゼロ過剰ポアソン分布は実装が面倒だったので妥協しています。
- 集計期間を広くする
一日のツイート数ではなく、一週間のツイート数など、集計期間を長くとることで分布を調整する方法が考えられます。しかし、この方法ではポアソン分布になるかどうか怪しい & 期間を長くしすぎると中心極限定理が働いて正規分布になってしまって面白くない。
def calc_poisson_distribution(distribution): # (e^{-λ}λ^k)/k! に従うかどうか検定 # λ = 未知母数 (データから推定する) # X = クラス k(K回事象が起こる) # パラメータλを標本平均から推定する mu = calc_mean(range(len(distribution)), distribution) # 推定されたパラメータλからポアソン分布に従う場合の期待分布を求める poisson_distribution = np.zeros(MAX_TWEETS) for x in range(MAX_TWEETS): poisson_distribution[x] = calc_poisson(mu, x) return poisson_distribution def calc_zero_inflated_poisson_distribution(distribution): zero_num = distribution[0] zero_rate = distribution[0]/np.sum(distribution) # パラメータλを標本平均から推定する mu = calc_mean(range(1, len(distribution[1:])), distribution[1:]) # 推定されたパラメータλからポアソン分布に従う場合の期待分布を求める poisson_distribution = np.zeros(MAX_TWEETS) for x in range(1, MAX_TWEETS): poisson_distribution[x] = calc_poisson(mu, x) poisson_distribution[0] = zero_rate after_zero = poisson_distribution[1:] * np.sum(distribution[1:]) return np.array([zero_num] + list(after_zero), dtype=np.float64) def calc_mean(xs, distribution): sum_ = 0 for x, freq in zip(xs, distribution): sum_ += x*freq mu = sum_/np.sum(distribution) return mu def calc_poisson(mu, x): e_mu = np.e ** mu return mu**x / (e_mu * scipy.misc.factorial(x))
χ二乗検定
あるデータが特定の分布に従っているかどうかを判定するにはχ二乗検定を用います2。χ二乗統計量は以下の式で与えられます。
数学的な説明を取っ払うと、観測値と期待値の自乗誤差和を期待値で割って正規化しています。確率変数に基づく計算をやると、χ二乗分布に従うことが確認でき、この値がχ二乗分布から大きく外れているとχ二乗分布であることが棄却され、2つの分布は異なる分布であるという結論が導かれます。
今回の場合は同一の分布であることを確認したいので、χ二乗値が自由度((7-1)×(2-1)=6)の上側有意確率0.05のχ二乗値12.6よりも小さいと嬉しいです。
def chi_square_test(data_freq, expect_freq): def calc_df(shape_): df = 1 for len_ in shape_: df *= (len_ - 1) return df chi_square = np.sum(((data_freq - expect_freq)**2)/expect_freq) df = calc_df(data_freq.shape) text = 'X-squared = {:.4f}, df = {:d}'.format(chi_square, df) print(text) return (text)
可視化
matplotlibで、 - 観測データの分布(Observed) - ポアソン分布の理論分布(Poisson) - Two-parat ポアソン分布の理論分布(two-part Poisson) を可視化しています。
def draw_hist(data_dist, expect_dist, two_part_dist, text): fig, ax = plt.subplots(1) ax.set_title('Target period: 2020/09/01~2020/12/31') ax.bar(np.arange(len(data_dist)), data_dist, width=0.2, label='Observed', color='#008000') ax.bar(np.arange(len(data_dist))+0.2, expect_dist, width=0.2, label='Poisson', color='salmon') ax.bar(np.arange(len(data_dist))+0.4, two_part_dist, width=0.2, label='two-part Poisson', color='lightblue') ax.legend(loc='best') ax.text(1.5, 50, text) ax.set_xlabel('Tweets per day') ax.set_ylabel('freq') plt.show() plt.close()
結果
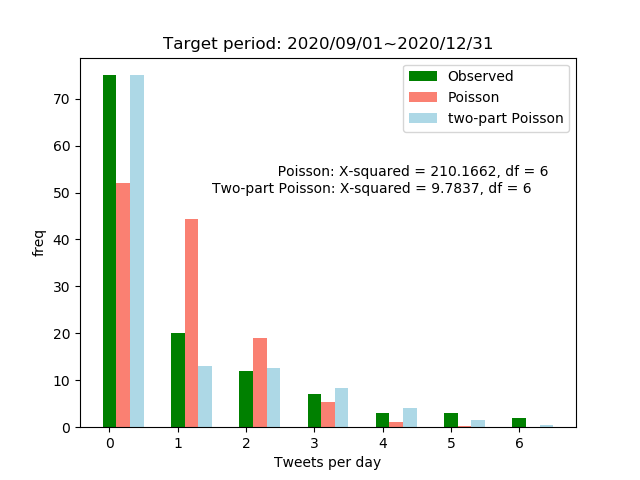
考察(というか感想)
- 無意識にツイートしていただけなのに、(条件はつくものの)ポアソン分布に従うことがわかって驚き
- よくツイートする人なら一様分布や正規分布のような形になるのだろうか。
- ポアソン分布に従っているからといって特に何か知見が得られたわけではない。あまりツイートしていないことが再確認された。
- 普通のポアソン分布の方をRでも一致することを確認済。
o <- c(75, 20, 12, 7, 3, 3, 2)
e <- c(5.20165547e+01, 4.43419811e+01, 1.88998608e+01, 5.37045225e+00,
1.14452261e+00, 1.95131724e-01, 2.77236329e-02)
chisq.test(o, p = e / sum(e))
qchisq(.95, df=6) # χ二乗値の確認 12.59159
# 出力結果:
Chi-squared test for given probabilities
data: o
X-squared = 210.16, df = 6, p-value < 2.2e-16